VisualCOMET+: Visual Commonsense Generation & its incorporation into a Multimodal Topic Modeling algorithm
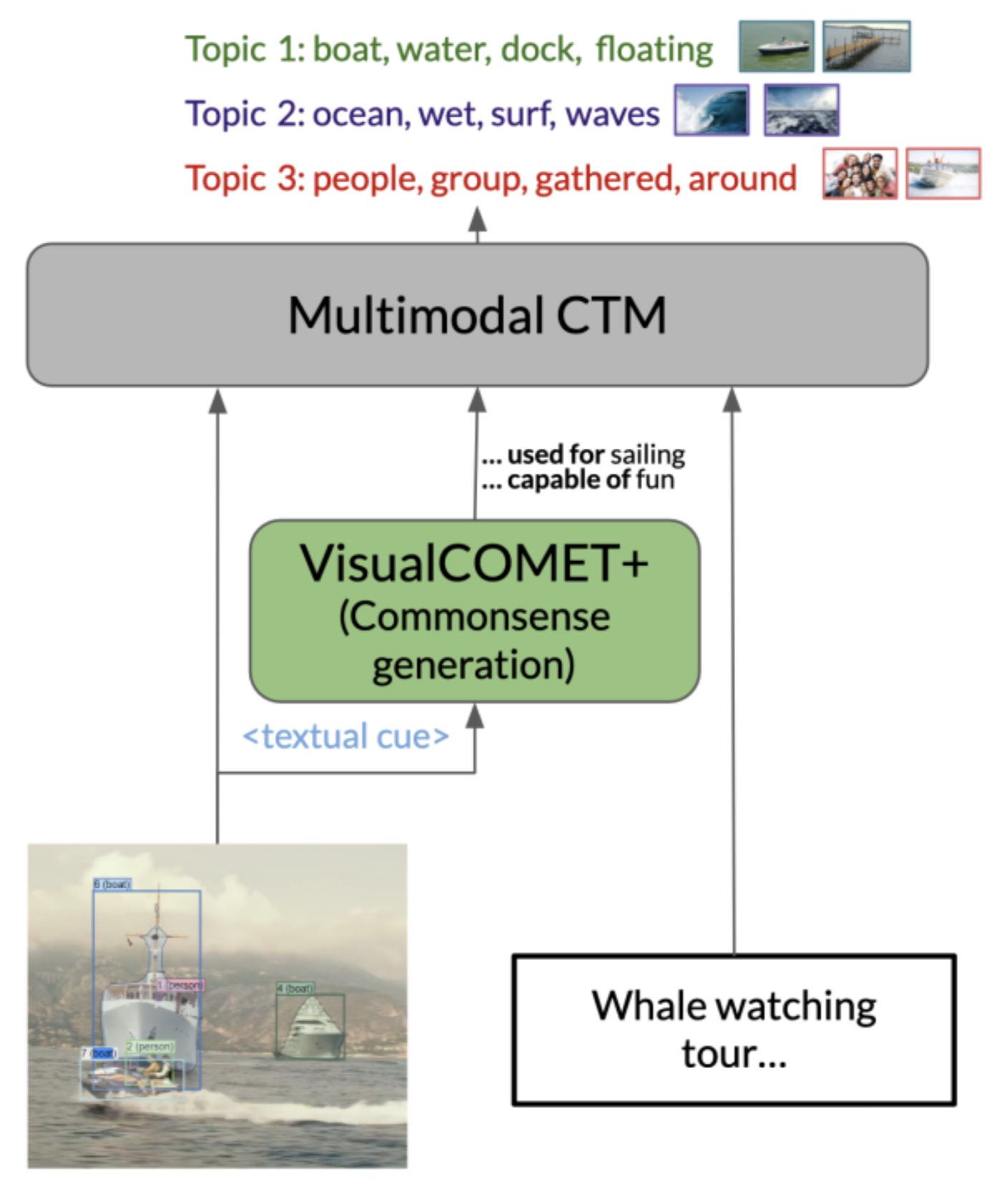
The task of commonsense knowledge generation is largely limited to the language domain, with models such as COMET (for explicit knowledge) and GPT-3 (for implicit knowledge). Moreover, VisualCOMET, a commonsense generation model that utilizes the visual context, is limited to three people-centric relations. Since commonsense generation on entire scenes, or parts of a scene, can be helpful in several downstream multimodal tasks, including VQA and topic modeling, we propose a general-purpose visual commonsense generation model, VisualCOMET+, by extending VisualCOMET with four diverse inference relations. Using the clue-rationale pairs from a visual abductive reasoning dataset, we train our commonsense generation model by creating groundtruth structured commonsense triplets. Then, we show that we can get coherent and more diverse topics by incorporating generated commonsense inferences and visual features into a novel multimodal topic modeling algorithm, Multimodal CTM.
Report