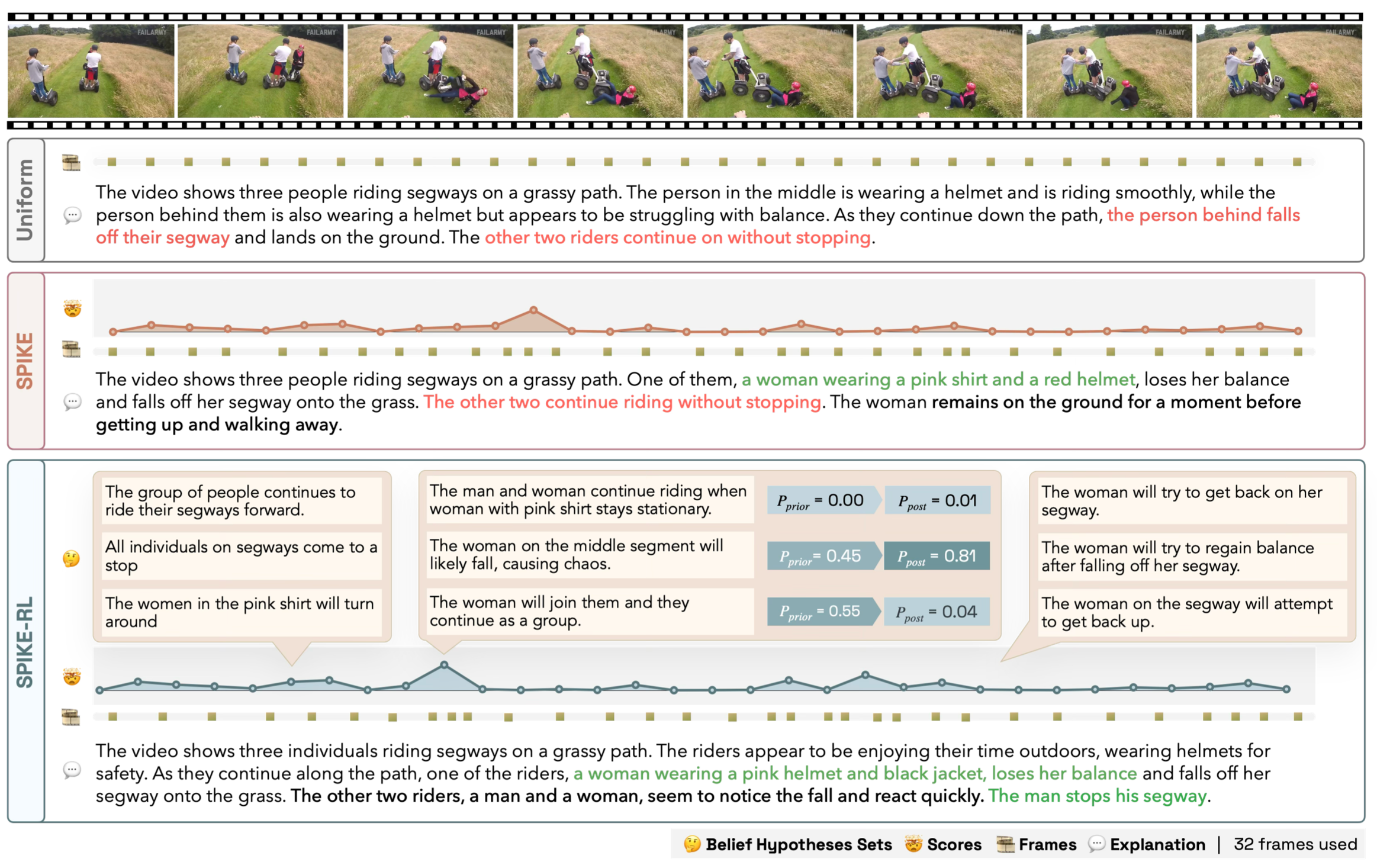
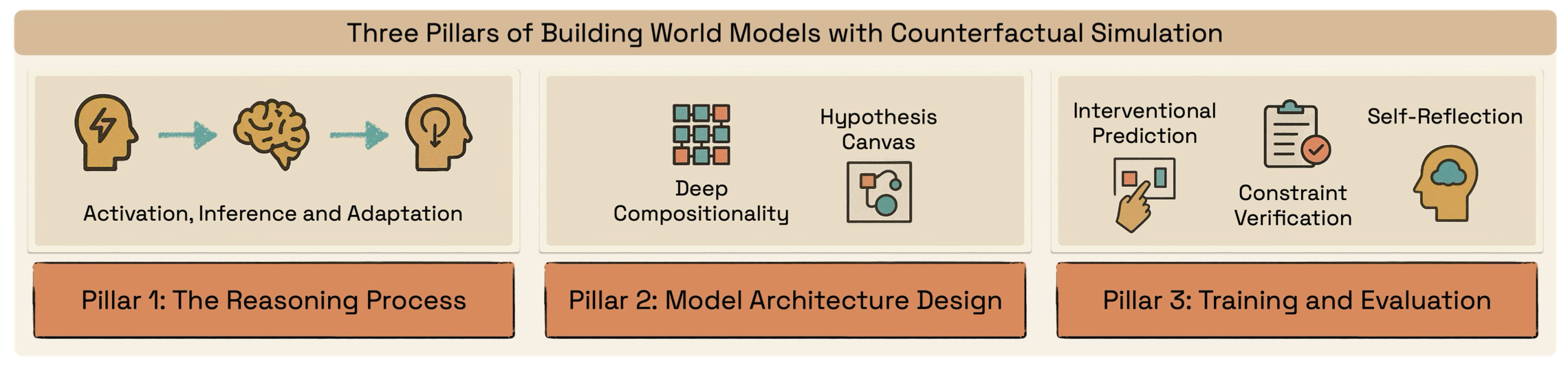
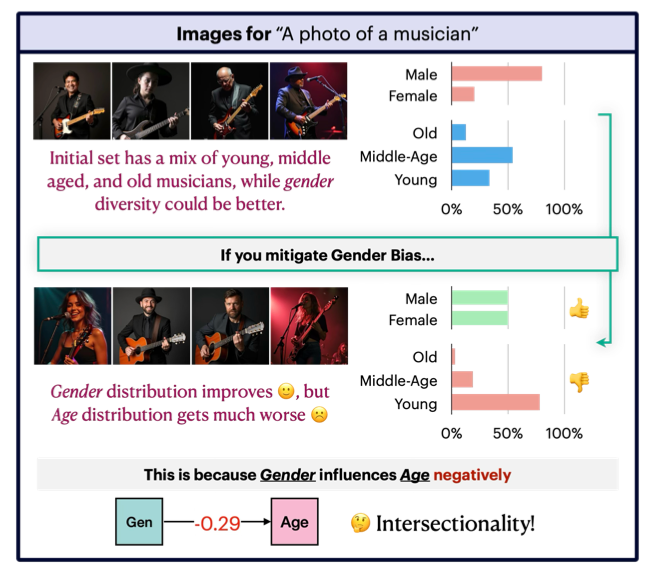
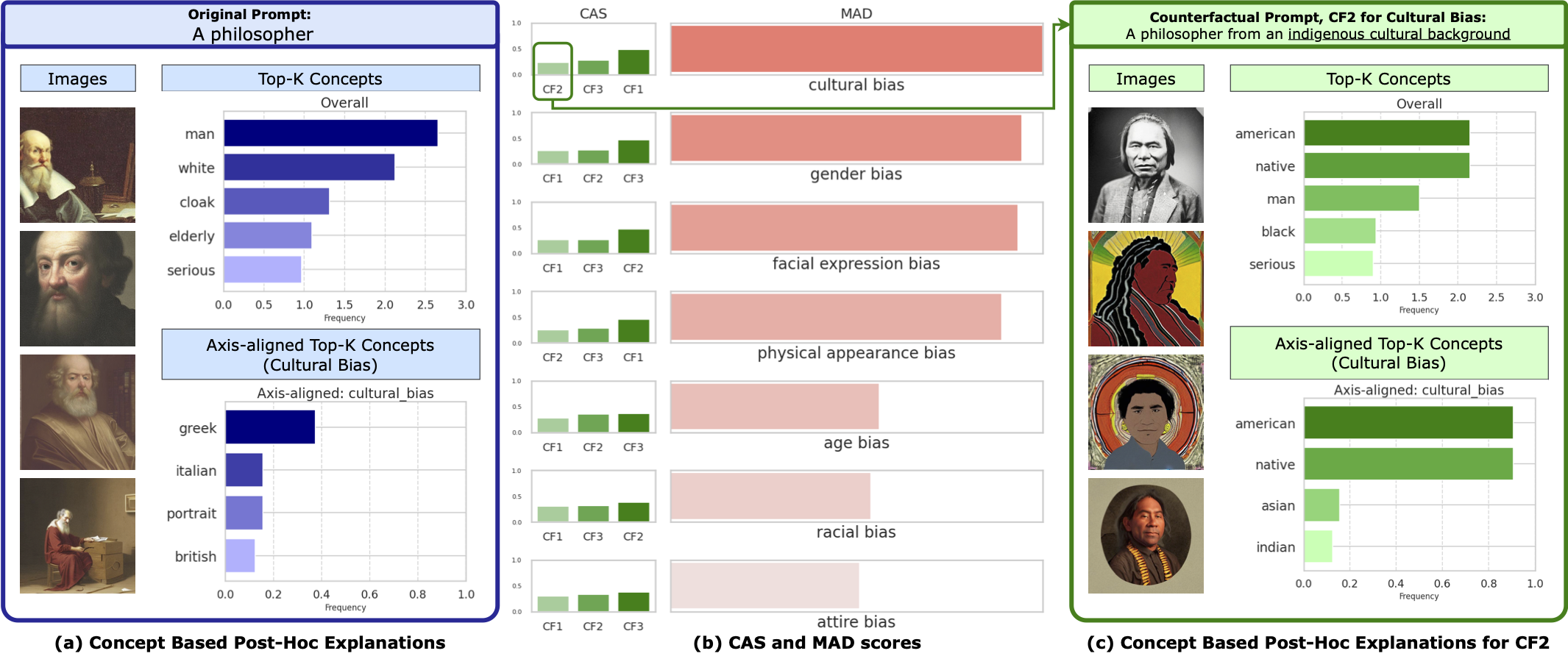
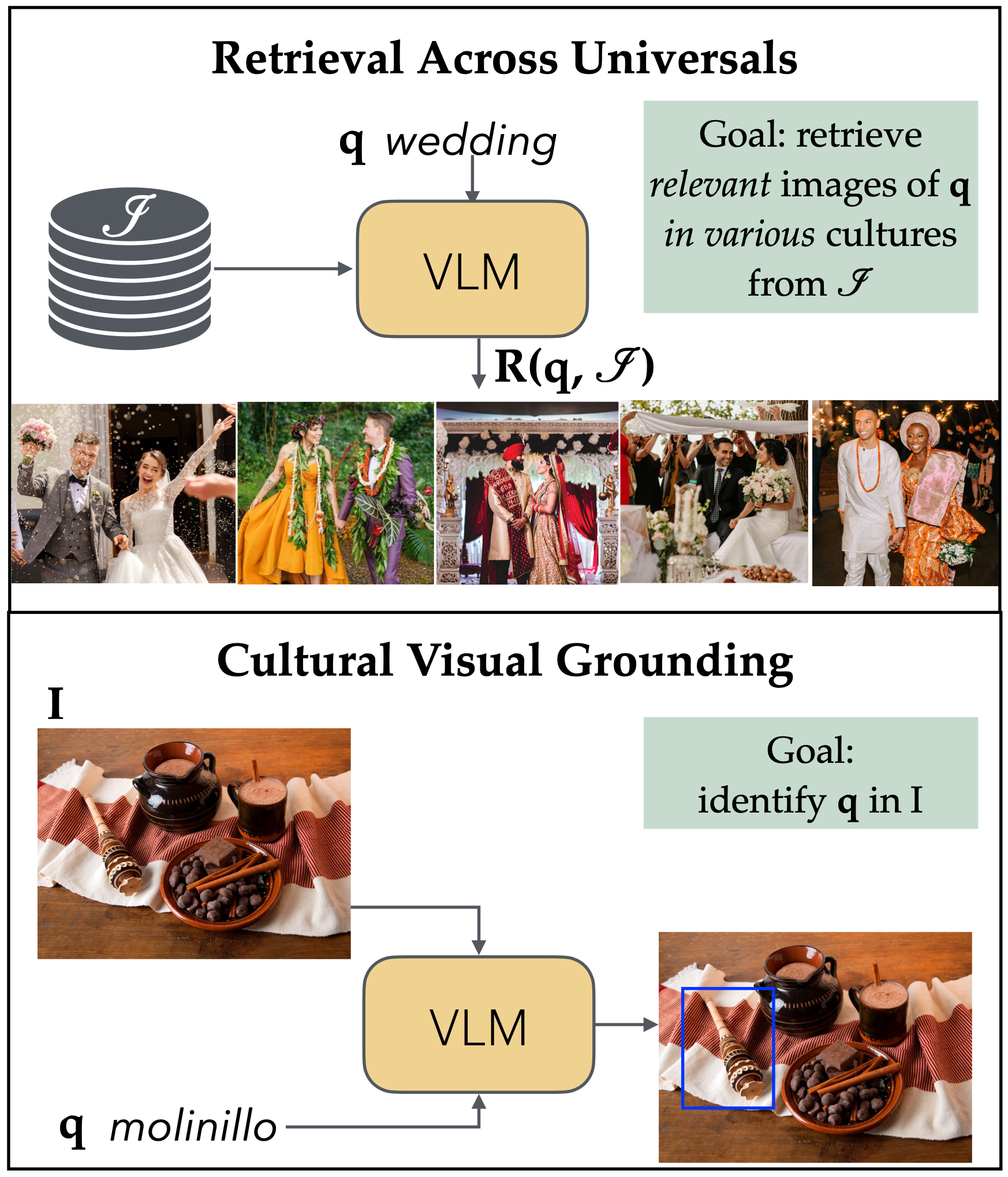
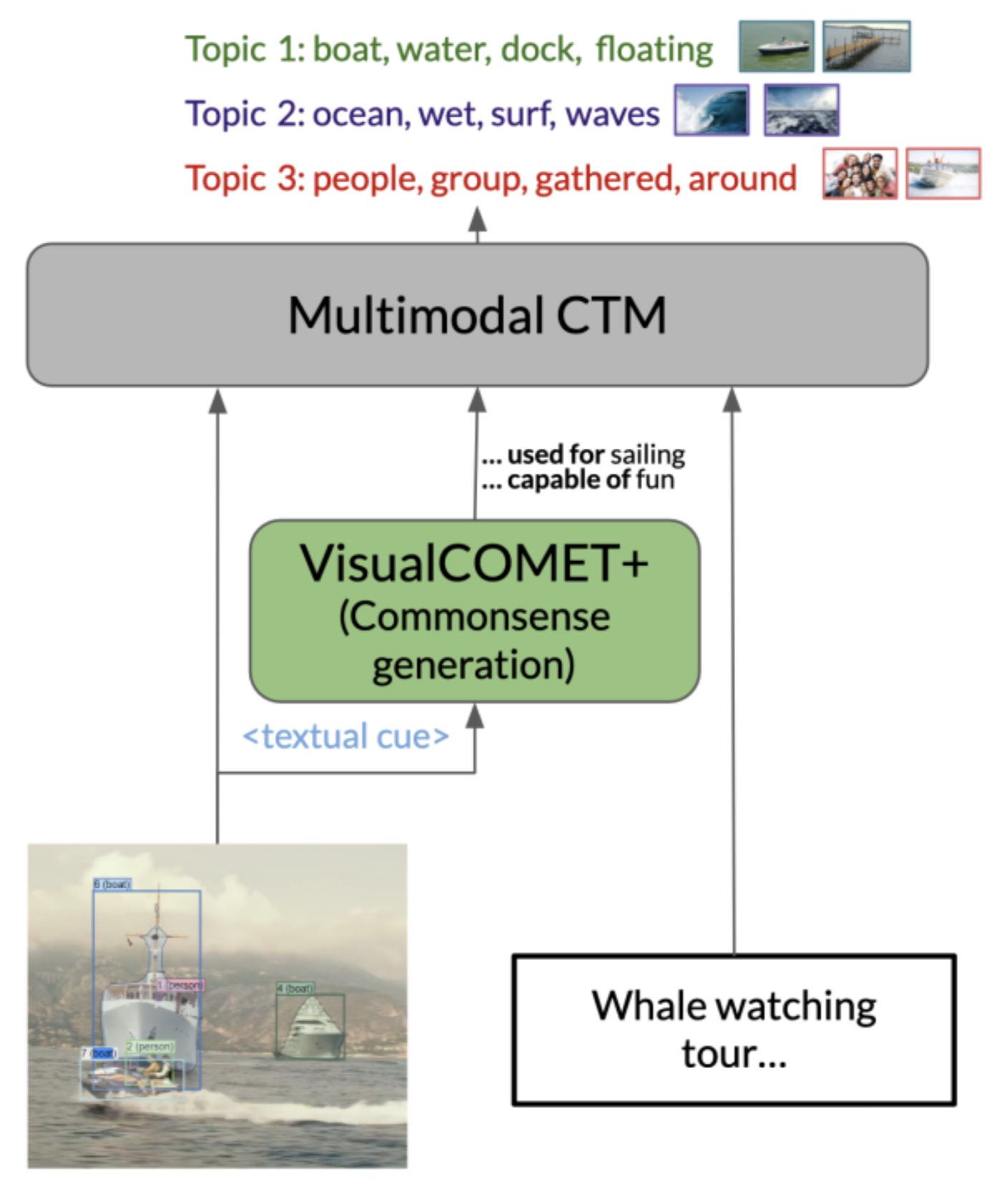
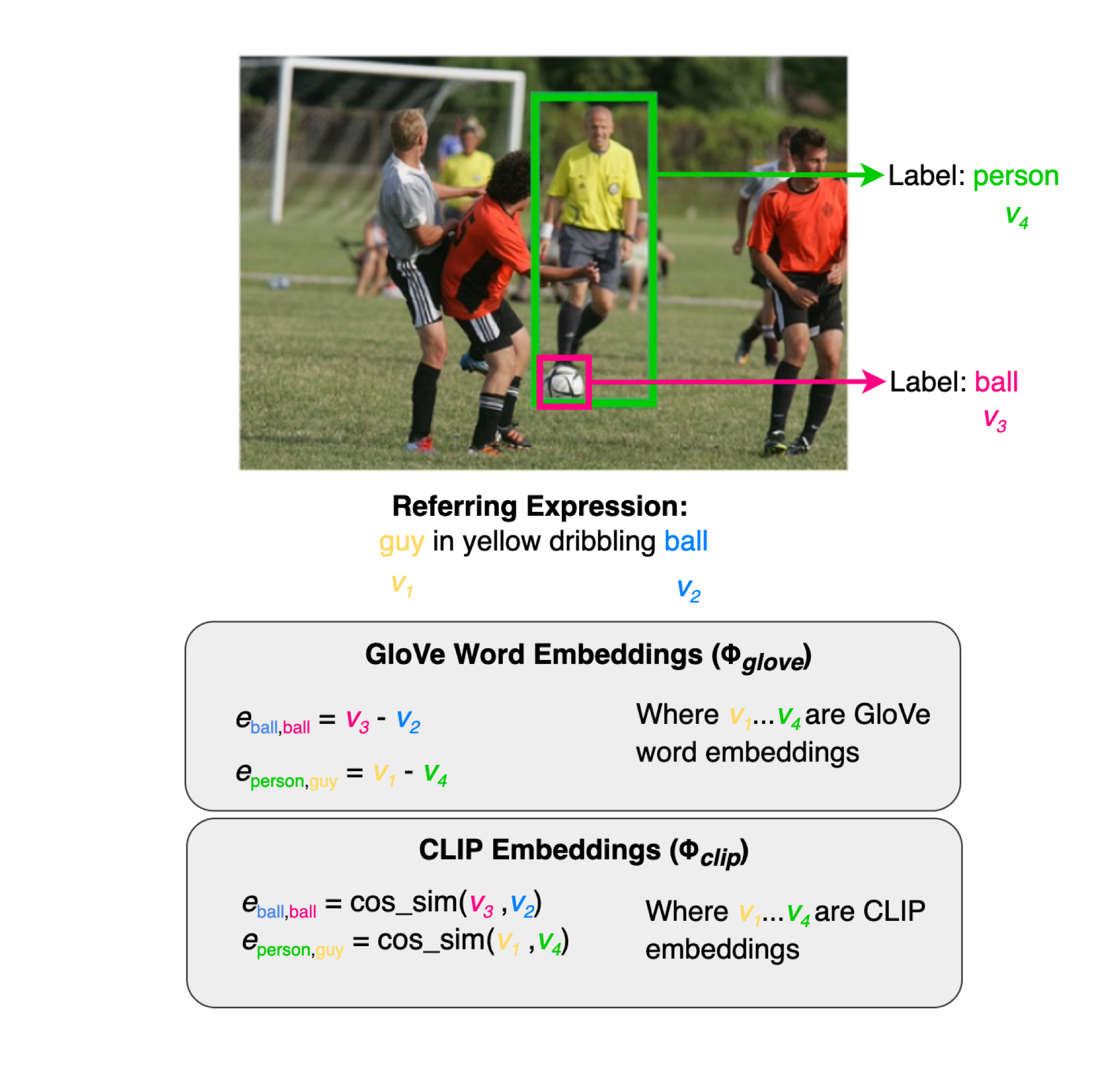
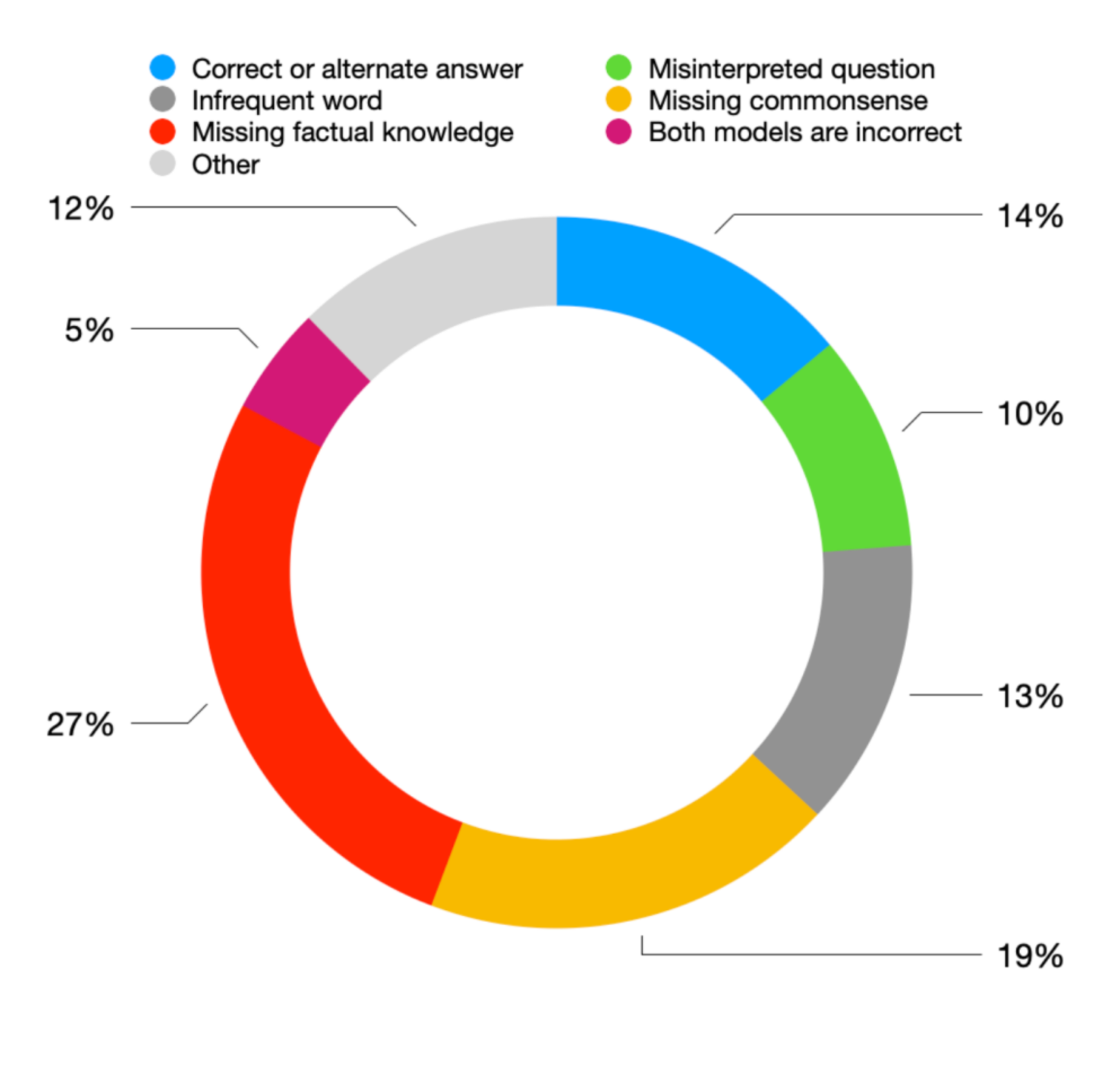
Spotlight: Identifying and Localizing Video Generation Errors Using VLMs
Jun 01, 2026Spotlight is a benchmark for evaluating whether VLMs can detect, localize, and explain fine-grained errors in high-fidelity text-to-video generations, with 600 videos and over 1,600 annotated error localizations.
ECCV 2026