Investigating extensions to VLC-BERT and comparing it with GPT-3
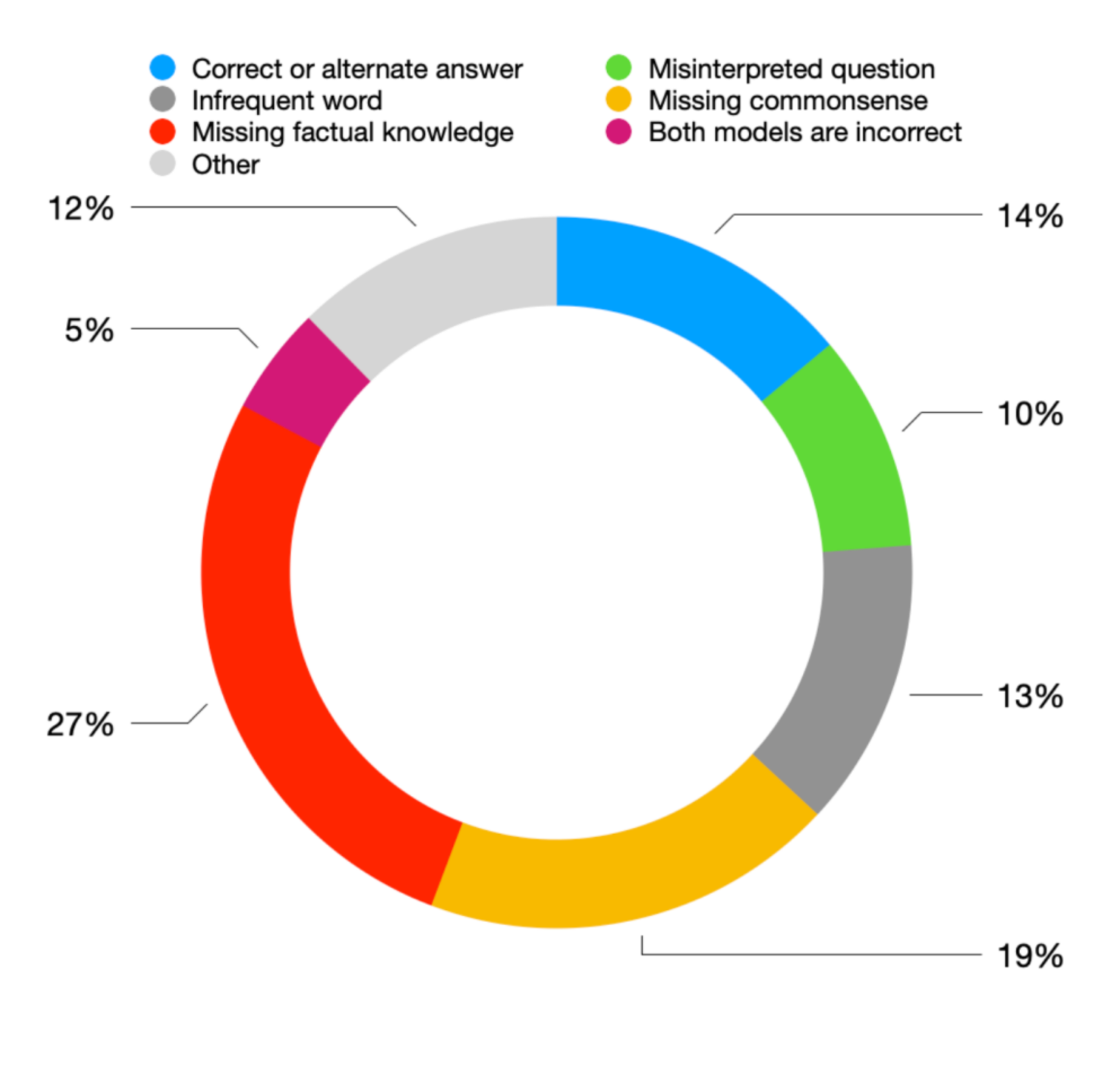
Visual Question Answering with commonsense reasoning is a challenging task that requires models to understand of the image, the question, and contextualized commonsense knowledge to assist with the reasoning required to arrive at an answer. In our work, we propose extensions to the VLC-BERT, aimed at solving two drawbacks of the model by identifying potential words in the input sequence that may answer the question using a Pointer Generator, and incorporating additional image information in the form of object tags from an object detection model. Our evaluation shows that the Pointer Generator and object detection models help achieve higher scores on the OK-VQA dataset. Furthermore, we generate answers using GPT-3 and incorporate them into VLC-BERT. Our error analysis on GPT-3 and VLC-BERT models highlight that GPT-3 contains valuable implicit commonsense and factual knowledge that is beneficial to our model.
Report